|
I was a researcher at ByteDance Research. Before that, I obtained my Ph.D. degree from University of Science and Technology of China (USTC), My advisors are Jiebo Luo and Houqiang Li. I received the B.S. degree from School of the Gifted Young, USTC. I spent joyful and fulfilling times at NUS, Tencent WeChat, Shanghai AI Lab, Microsoft Research Asia (MSRA). |

|
|
|
|
I'm interested in Multi-Modal Learning, Computer Vision, and Machine Learning. Much of my research is about Vision-and-Language Pre-training. Representative papers are highlighted. (* indicates equal contribution) |
|
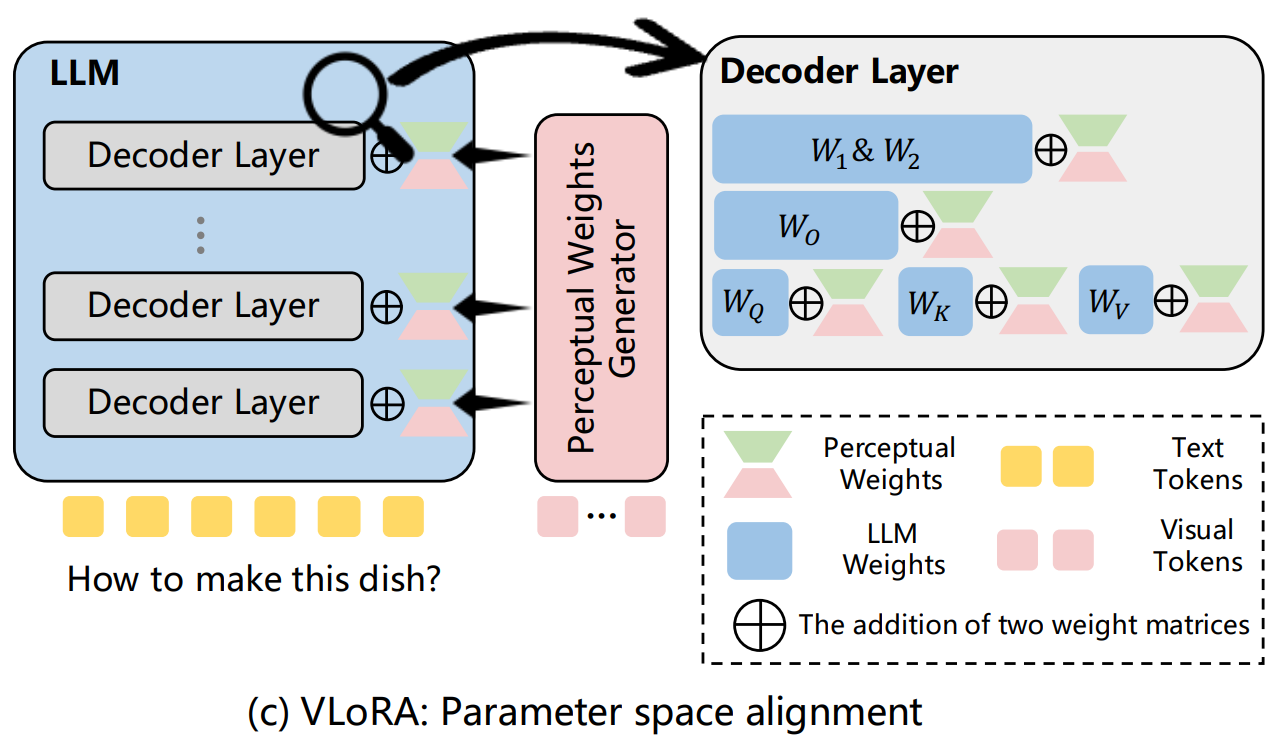
Feipeng Ma, Hongwei Xue (project lead), Yizhou Zhou, Guangting Wang, Fengyun Rao, Shilin Yan, Yueyi Zhang, Siying Wu, Mike Zheng Shou, Xiaoyan Sun NeurIPS, 2024 [PDF] [Project Page] [Code] We propose a novel parameter space alignment paradigm for MLLMs to address the inefficiency of input space alignment paradigm in visual perception, introducing VLoRA that converts visual features to LoRA weights, achieving comparable performance on various benchmarks while significantly reducing computational costs for training and inference. |
|
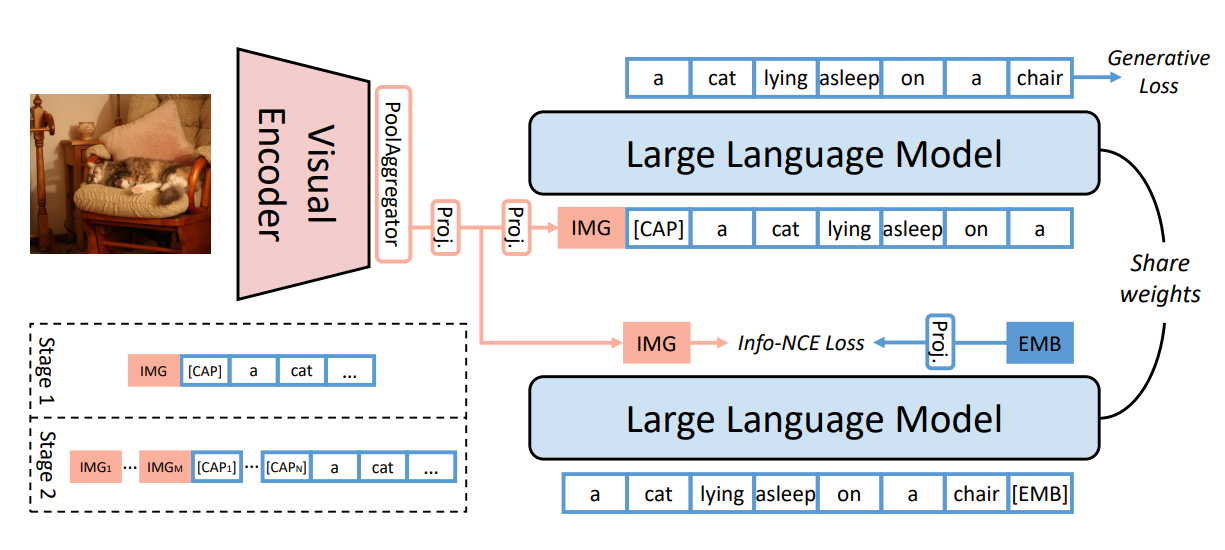
Feipeng Ma, Hongwei Xue (project lead), Guangting Wang, Yizhou Zhou, Fengyun Rao, Shilin Yan, Yueyi Zhang, Siying Wu, Mike Zheng Shou, Xiaoyan Sun Arxiv [PDF] [arXiv] We propose a Multi-Modal Generative Embedding Model (MM-GEM), whereby the generative and embedding objectives are encapsulated in one Large Language Model. we explore the minimalism of multi-modal paradigm in this work. |
|
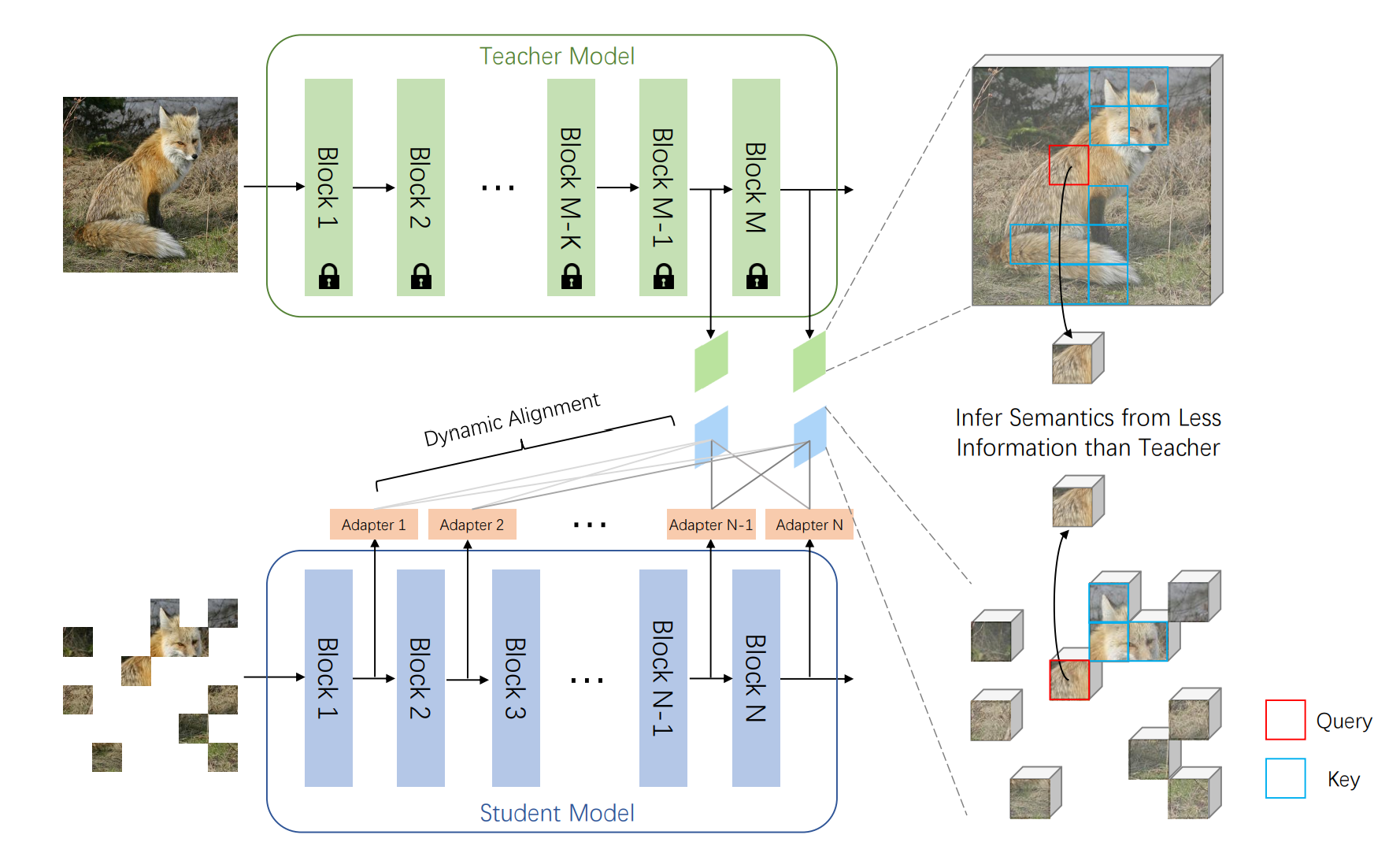
Hongwei Xue, Peng Gao, Hongyang Li, Yu Qiao, Hao Sun, Houqiang Li, Jiebo Luo CVPR, 2023 [PDF] [arXiv] [Code] we propose an efficient MIM paradigm named MaskAlign. MaskAlign simply learns the consistency of visible patch features extracted by the student model and intact image features extracted by the teacher model. |
|
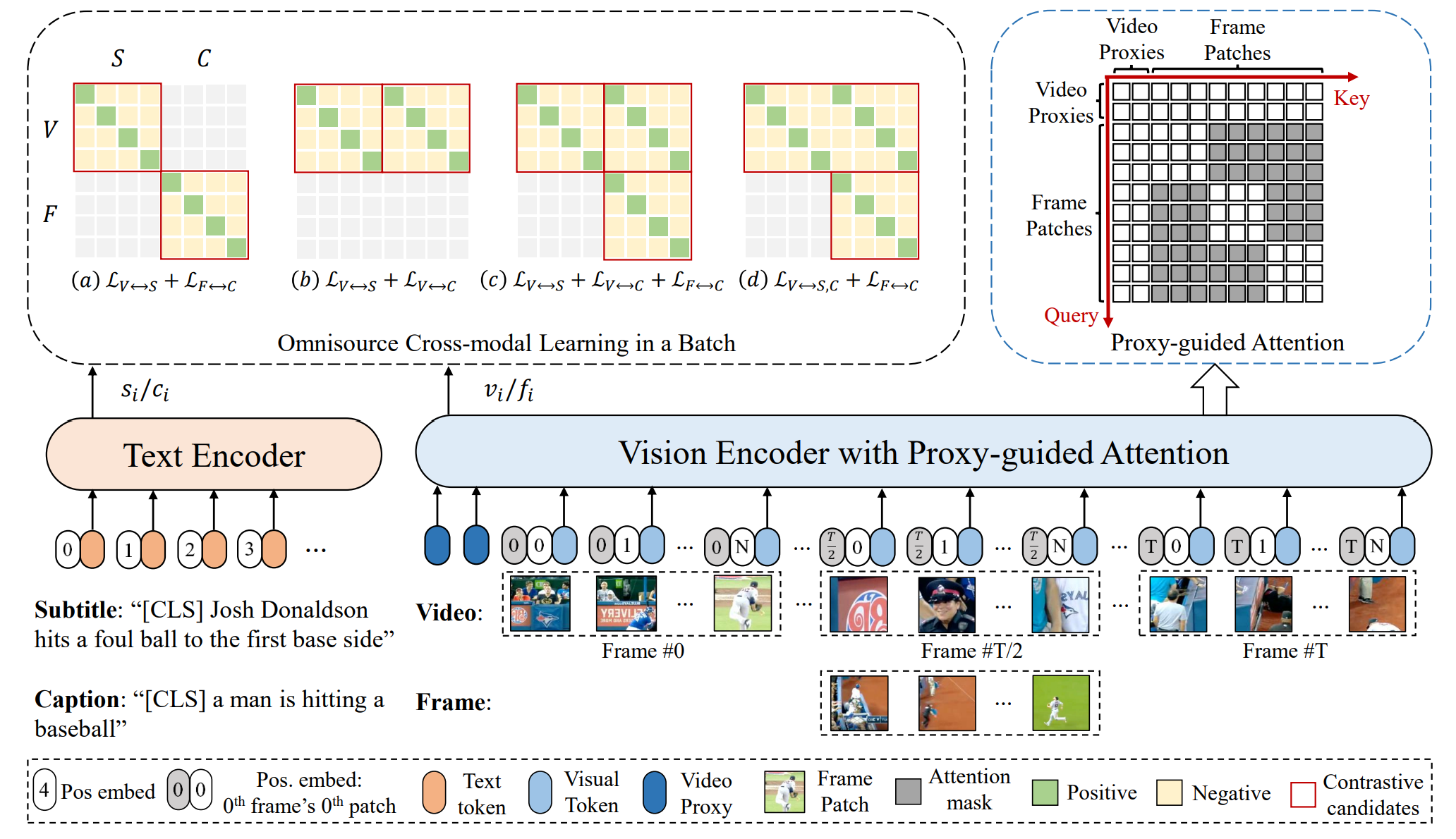
Hongwei Xue*, Yuchong Sun*, Bei Liu, Jianlong Fu, Ruihua Song, Houqiang Li, Jiebo Luo ICLR, 2023 [PDF] [arXiv] [Code] [PaperWithCode] We adapt image-text pre-trained models to video-text pre-training (i.e., post-pretraining). In this work, we propose an Omnisource Cross-modal Learning method equipped with a Video Proxy mechanism on the basis of CLIP, namely CLIP-ViP. |
|
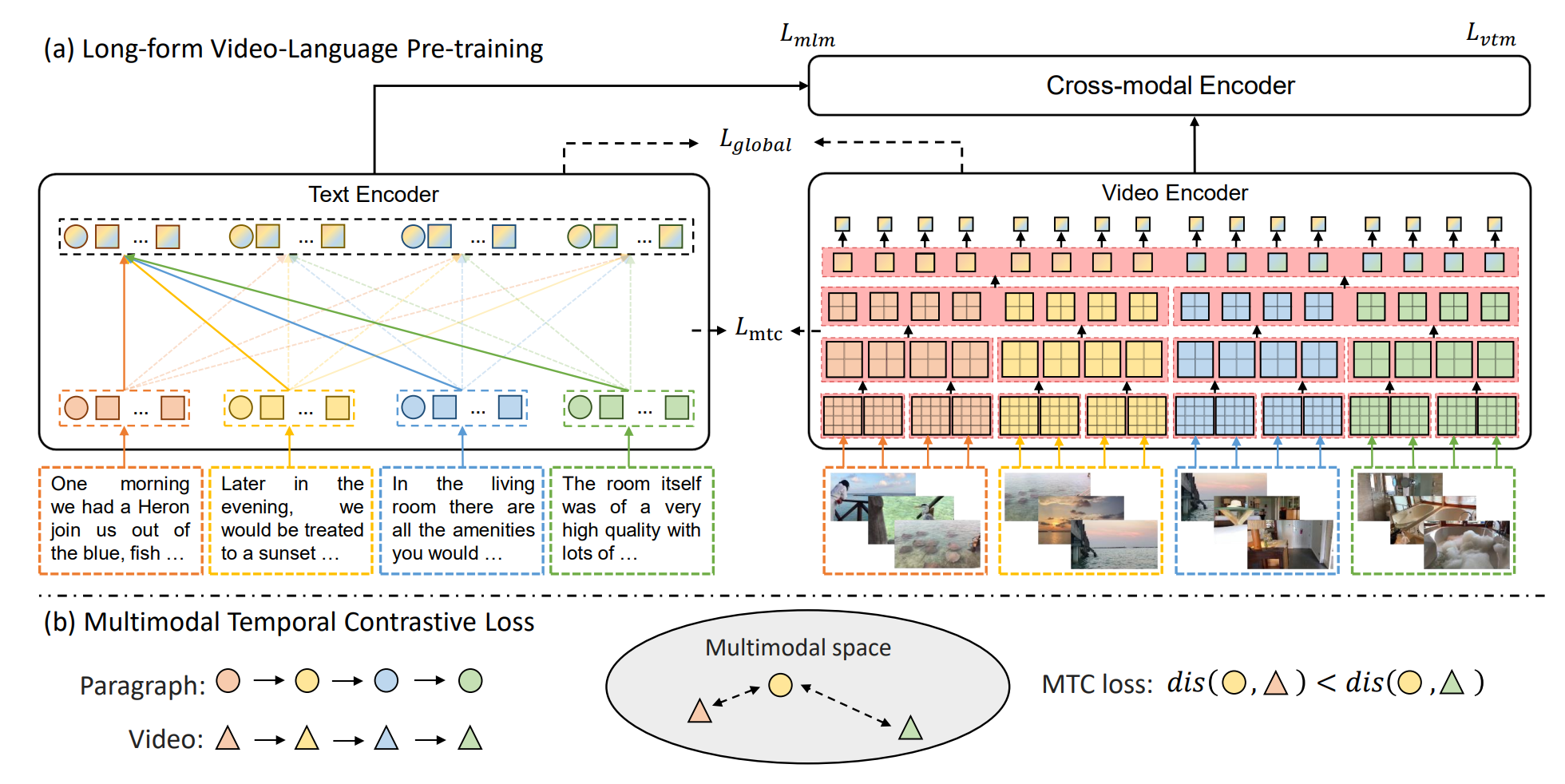
Yuchong Sun, Hongwei Xue, Ruihua Song, Bei Liu, Huan Yang, Jianlong Fu NeurIPS, 2022 [PDF] [arXiv] [Code] We introduce a Long-Form VIdeo-LAnguage pre-training model (LF-VILA) and train it on a large-scale long-form video and paragraph dataset constructed from HD-VILA-100M. |
|
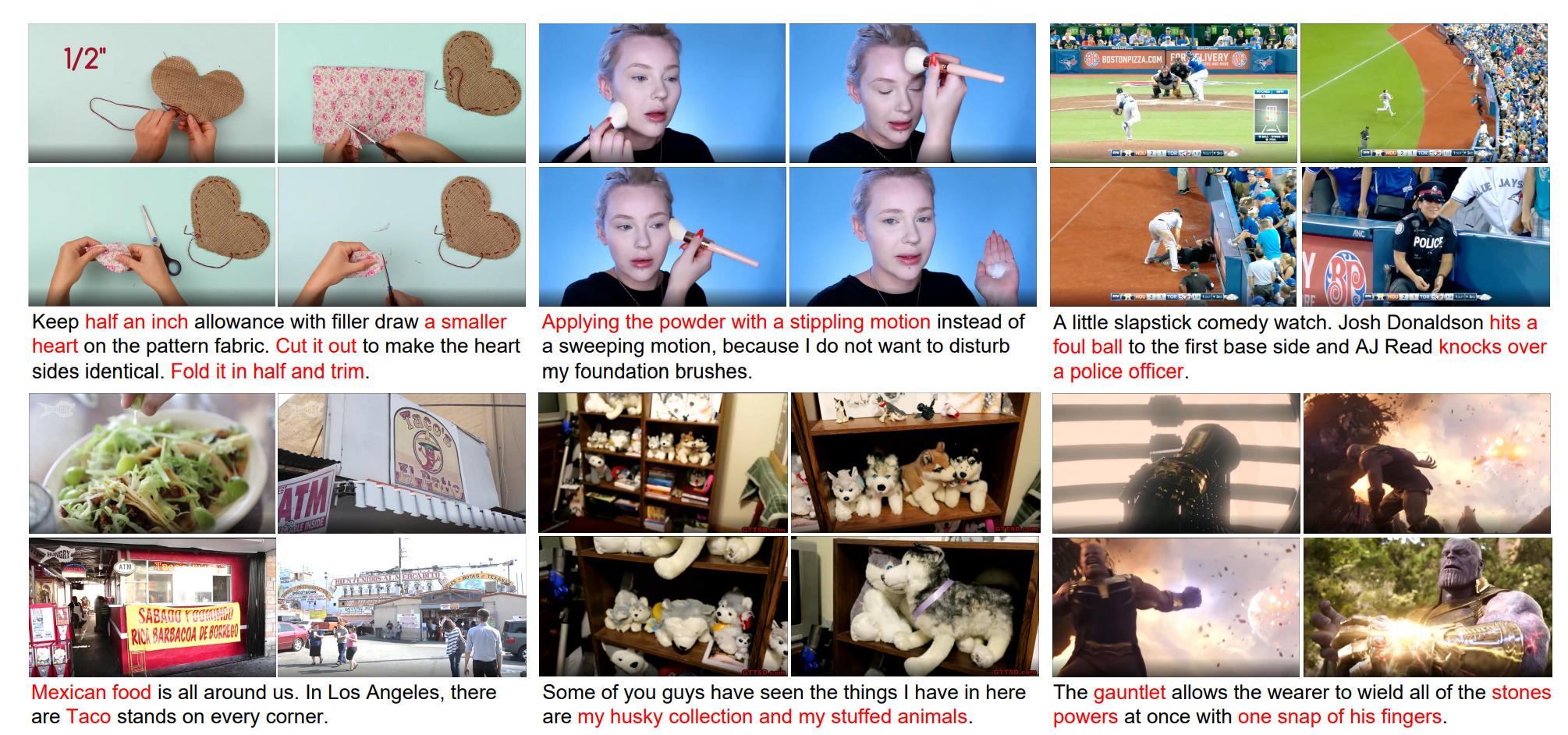
Hongwei Xue*, Tiankai Hang*, Yanhong Zeng*, Yuchong Sun*, Bei Liu, Huan Yang, Jianlong Fu, Baining Guo CVPR, 2022 [PDF] [arXiv] [Code] We collect a large dataset which is the first high-resolution dataset including 371.5k hours of 720p videos and the most diversified dataset covering 15 popular YouTube categories. |
|
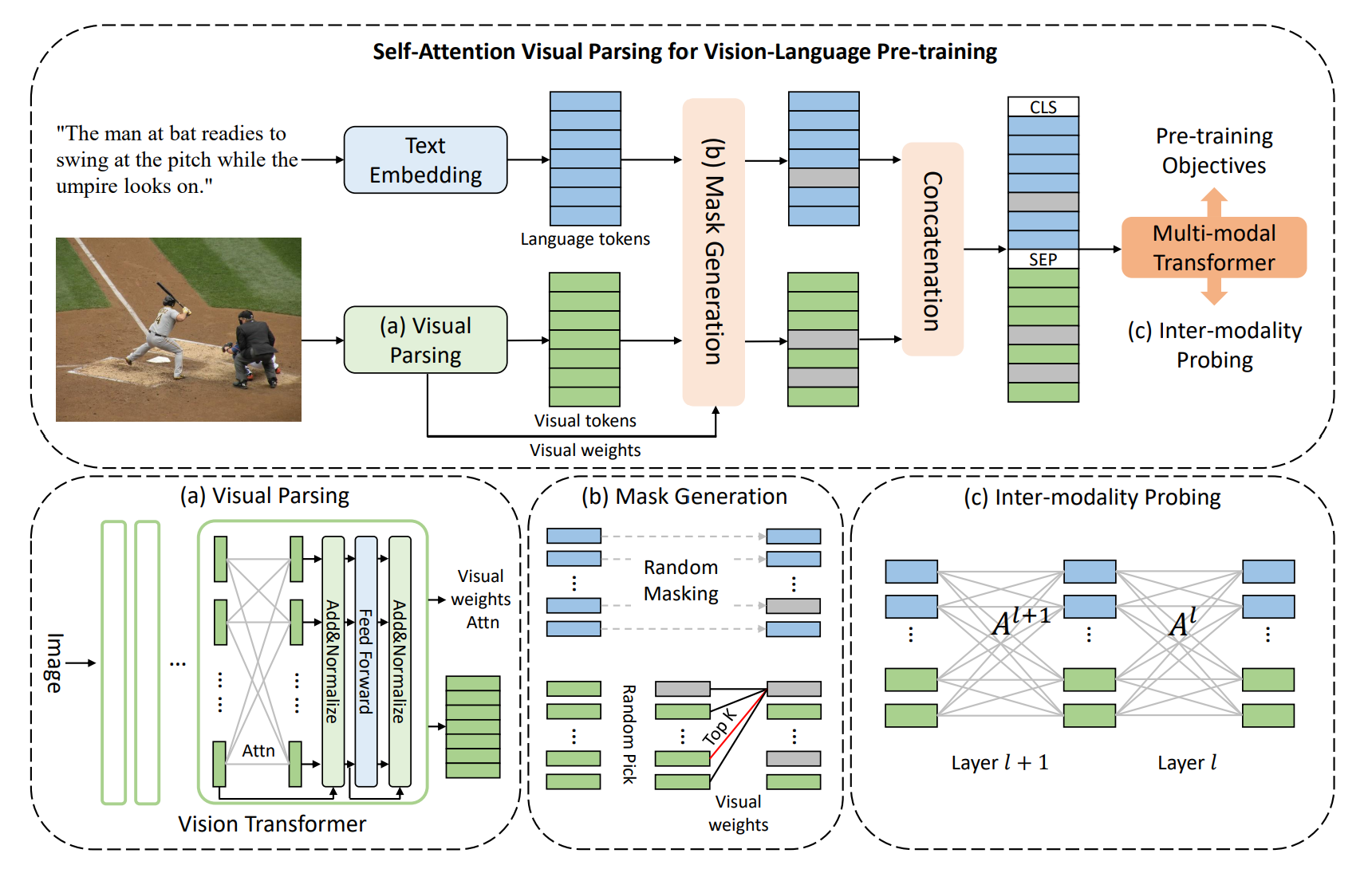
Hongwei Xue, Yupan Huang, Bei Liu, Houwen Peng, Jianlong Fu, Houqiang Li, Jiebo Luo NeurIPS, 2021 [PDF] [arXiv] [Supp] [Presentation] We propose a fully Transformer model for Vision-and-Language pre-training and explore to study the inter-modal interaction. |

|
Hongwei Xue, Yupan Huang, Bei Liu, Huan Yang, Jianlong Fu, Houqiang Li, Jiebo Luo ACM MM Oral, 2021 [PDF] [arXiv] We propose a model named FGLA to generate high-quality and realistic videos by learning Fine-Grained motion embedding for Landscape Animation. |
|
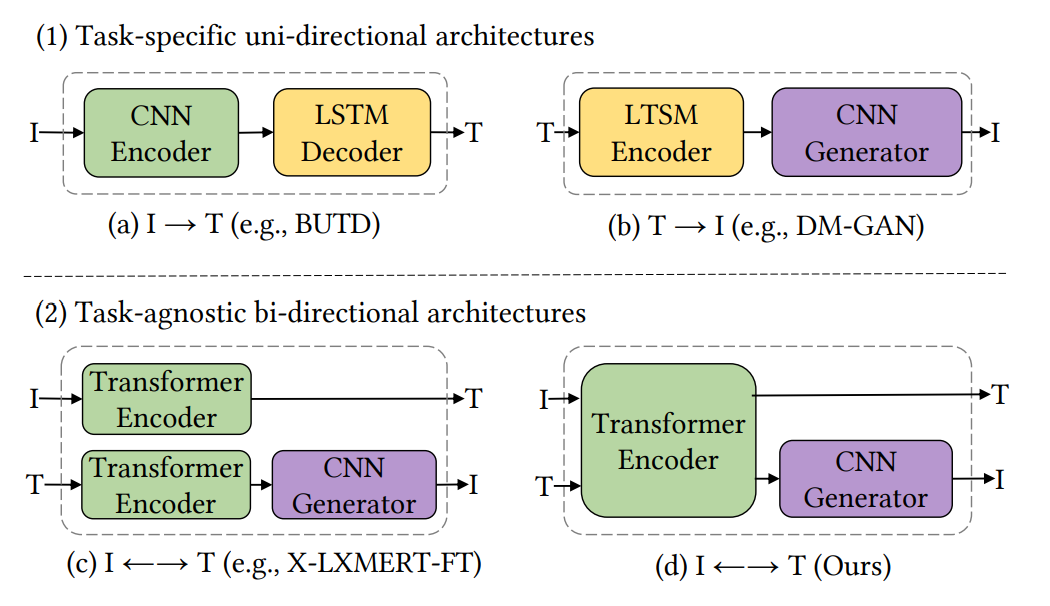
Yupan Huang, Hongwei Xue, Bei Liu, Yutong Lu ACM MM, 2021 [PDF] [arXiv] [Code] In this work, we propose a unified image-and-text generative framework based on a single multimodal model to jointly study the bi-directional tasks. |
|
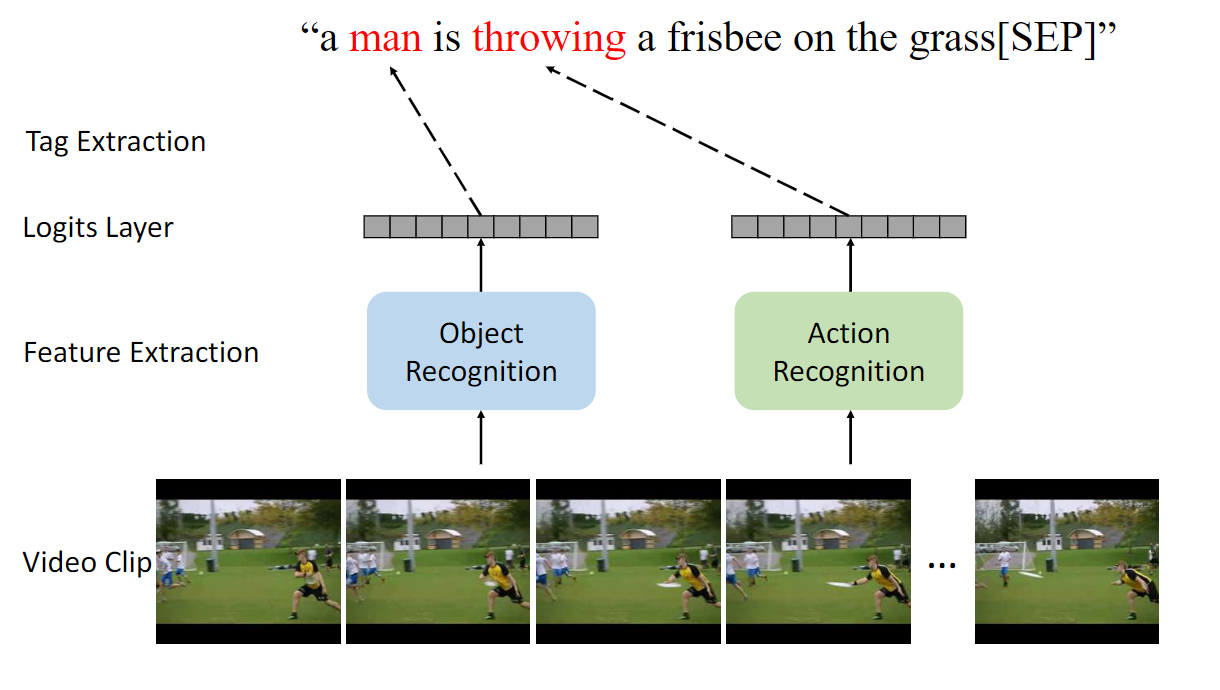
Yiqing Huang*, Hongwei Xue*, Jiansheng Chen, Huimin Ma, Hongbing Ma ACM MM, 2021 We propose to leverage the semantic tags to bridge the gap between the modalities of vision and language rather than directly concatenating or attending to the visual and linguistic features. |

|
Hongwei Xue, Haomiao Liu, Jun Li, Houqiang Li, Jiebo Luo ICME, 2020 We propose a deep Siamese network model to to classify different types of image edits between an original image and an edited image. |
|
|
|
|
Based on Jon Barron's website.
|